Tris et recherche
1. Tri par Sélection
Fonctionnement :
Le tri par sélection fonctionne en divisant le tableau en deux parties : une partie triée et une partie non triée. À chaque itération, l'algorithme cherche l'élément le plus petit dans la partie non triée et l'échange avec le premier élément de cette partie. Ainsi, la partie triée grandit d'un élément à chaque itération.
Exemple :
Prenons le tableau [64, 25, 12, 22, 11].
- Première itération : Le plus petit élément est
11. On l'échange avec64. Le tableau devient[11, 25, 12, 22, 64].
- Deuxième itération : Le plus petit élément dans la partie non triée est
12. On l'échange avec25. Le tableau devient[11, 12, 25, 22, 64].
- Troisième itération : Le plus petit élément est
22. On l'échange avec25. Le tableau devient[11, 12, 22, 25, 64].
- Quatrième itération : Le plus petit élément est
64, qui est déjà à sa place.
Le tableau est maintenant trié.
def tri_selection(tab):
n = len(tab)
for i in range(n - 1):
min_index = i
for j in range(i + 1, n):
if tab[j] < tab[min_index]:
min_index = j
tab[i], tab[min_index] = tab[min_index], tab[i]
# Exemple
liste = [64, 25, 12, 22, 11]
tri_selection(liste)
print(liste) # [11, 12, 22, 25, 64]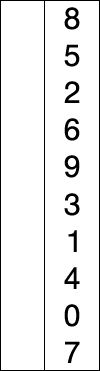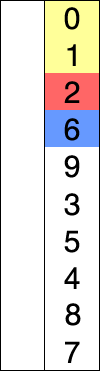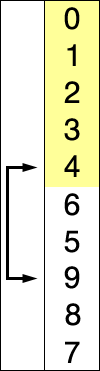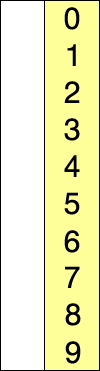
2. Tri par Insertion
Fonctionnement :
Le tri par insertion fonctionne en construisant progressivement une partie triée du tableau. À chaque itération, l'algorithme prend un élément de la partie non triée et l'insère à sa place dans la partie triée.
Exemple :
Prenons le tableau [12, 11, 13, 5, 6].
- Première itération : Le deuxième élément est
11. On le compare à12et on l'insère avant. Le tableau devient[11, 12, 13, 5, 6].
- Deuxième itération : Le troisième élément est
13, qui est déjà à sa place.
- Troisième itération : Le quatrième élément est
5. On le compare à13,12, et11, et on l'insère au début. Le tableau devient[5, 11, 12, 13, 6].
- Quatrième itération : Le cinquième élément est
6. On le compare à13,12, et11, et on l'insère entre5et11. Le tableau devient[5, 6, 11, 12, 13].
Le tableau est maintenant trié.
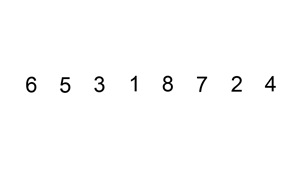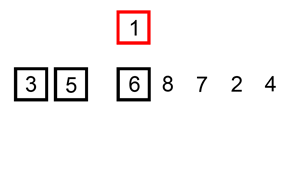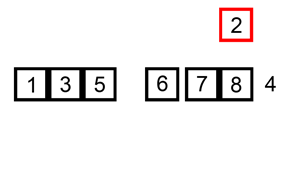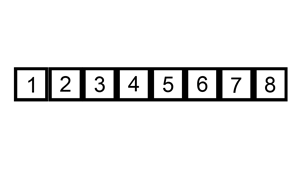
def tri_insertion(tab):
n = len(tab)
for i in range(1, n):
cle = tab[i]
j = i - 1
while j >= 0 and tab[j] > cle:
tab[j + 1] = tab[j] # Décaler à droite
j -= 1
tab[j + 1] = cle
# Exemple
liste = [12, 11, 13, 5, 6]
tri_insertion(liste)
print(liste) # [5, 6, 11, 12, 13]3. Tri par Fusion (Merge Sort)
Fonctionnement :
Le tri par fusion est un algorithme de tri récursif qui divise le tableau en deux moitiés, trie chaque moitié, puis fusionne les deux moitiés triées. La fusion consiste à combiner deux listes triées en une seule liste triée.
Exemple :
Prenons le tableau [38, 27, 43, 3, 9, 82, 10].
- Division : Le tableau est divisé en
[38, 27, 43]et[3, 9, 82, 10].
- Tri récursif : Chaque moitié est triée récursivement.
[38, 27, 43]devient[27, 38, 43]et[3, 9, 82, 10]devient[3, 9, 10, 82].
- Fusion : Les deux moitiés triées sont fusionnées en une seule liste triée
[3, 9, 10, 27, 38, 43, 82].
Le tableau est maintenant trié.
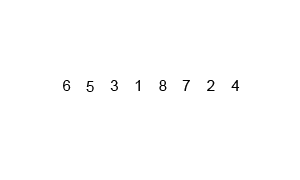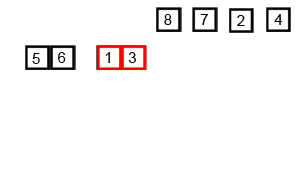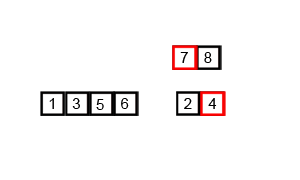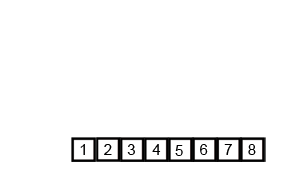
def fusion(gauche, droite):
resultat = []
i = j = 0
while i < len(gauche) and j < len(droite):
if gauche[i] <= droite[j]:
resultat.append(gauche[i])
i += 1
else:
resultat.append(droite[j])
j += 1
# Ajouter le reste des éléments
resultat.extend(gauche[i:])
resultat.extend(droite[j:])
return resultat
def tri_fusion(tab):
if len(tab) <= 1:
return tab
milieu = len(tab) // 2
gauche = tri_fusion(tab[:milieu])
droite = tri_fusion(tab[milieu:])
return fusion(gauche, droite)
# Exemple
liste = [38, 27, 43, 3, 9, 82, 10]
liste_triee = tri_fusion(liste)
print(liste_triee) # [3, 9, 10, 27, 38, 43, 82]4. Tri Rapide (Quick Sort)
Fonctionnement :
Le tri rapide est un algorithme de tri récursif qui choisit un élément pivot, puis partitionne le tableau en deux parties : une partie avec les éléments plus petits que le pivot et une partie avec les éléments plus grands que le pivot. Chaque partie est ensuite triée récursivement.
Exemple :
Prenons le tableau [10, 7, 8, 9, 1, 5].
- Choix du pivot : Le premier élément
10est choisi comme pivot.
- Partitionnement : Le tableau est partitionné en
[7, 8, 9, 1, 5]et[](car il n'y a pas d'éléments plus grands que10).
- Tri récursif : La partie
[7, 8, 9, 1, 5]est triée récursivement. Le pivot7est choisi, et le tableau est partitionné en[1, 5]et[8, 9].
- Fusion : Les parties triées sont combinées pour donner
[1, 5, 7, 8, 9, 10].
Le tableau est maintenant trié.
def tri_rapide(tab):
if len(tab) <= 1:
return tab
pivot = tab[0]
moins = [x for x in tab[1:] if x <= pivot]
plus = [x for x in tab[1:] if x > pivot]
return tri_rapide(moins) + [pivot] + tri_rapide(plus)
# Exemple
liste = [10, 7, 8, 9, 1, 5]
liste_triee = tri_rapide(liste)
print(liste_triee) # [1, 5, 7, 8, 9, 10]
5. Tri à Bulle (Bubble Sort)
Fonctionnement :
Le tri à bulle fonctionne en comparant chaque paire d'éléments voisins et en les échangeant s'ils sont dans le mauvais ordre. Ce processus est répété jusqu'à ce que le tableau soit trié.
Exemple :
Prenons le tableau [5, 1, 4, 2, 8].
- Première itération : On compare
5et1et on les échange. Le tableau devient[1, 5, 4, 2, 8]. On compare5et4et on les échange. Le tableau devient[1, 4, 5, 2, 8]. On compare5et2et on les échange. Le tableau devient[1, 4, 2, 5, 8]. On compare5et8et on ne les échange pas.
- Deuxième itération : On compare
1et4et on ne les échange pas. On compare4et2et on les échange. Le tableau devient[1, 2, 4, 5, 8]. On compare4et5et on ne les échange pas. On compare5et8et on ne les échange pas.
- Troisième itération : Le tableau est déjà trié, donc aucune échange n'est nécessaire.
Le tableau est maintenant trié.
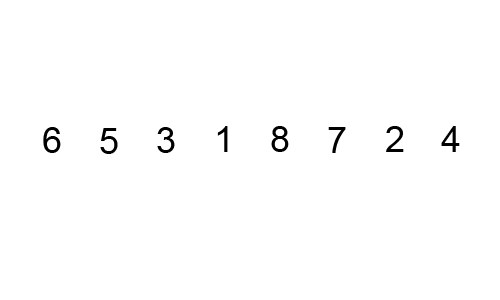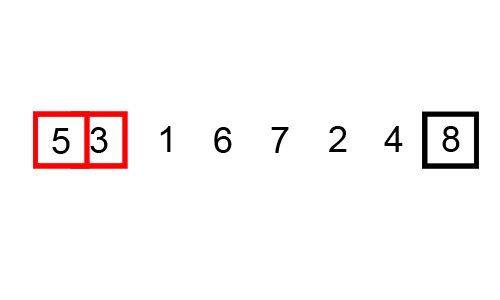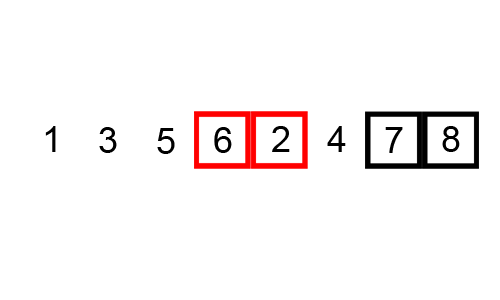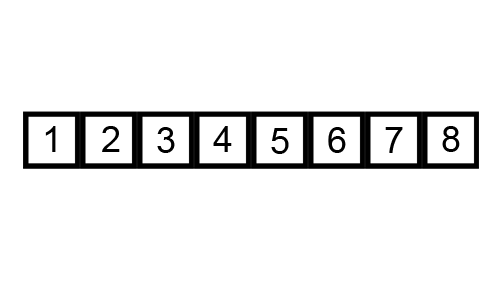
def tri_bulle(tab):
n = len(tab)
for i in range(n):
for j in range(0, n - i - 1):
if tab[j] > tab[j + 1]:
tab[j], tab[j + 1] = tab[j + 1], tab[j]
# Exemple
liste = [5, 1, 4, 2, 8]
tri_bulle(liste)
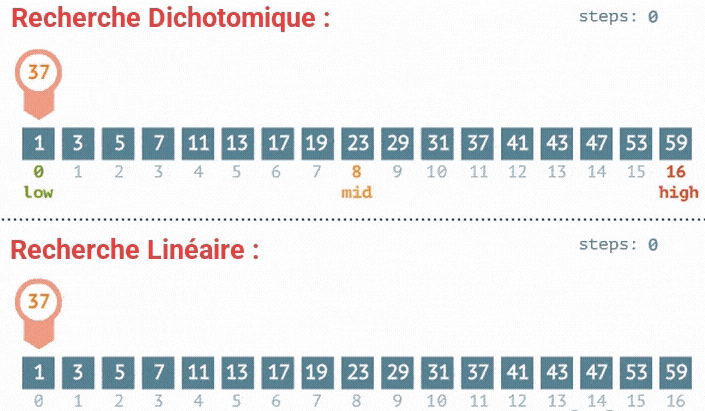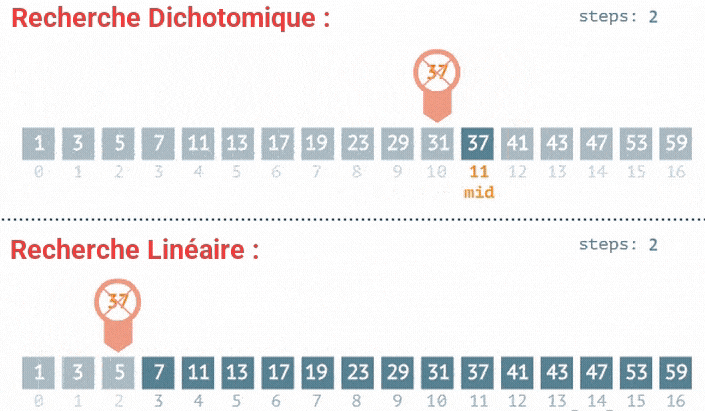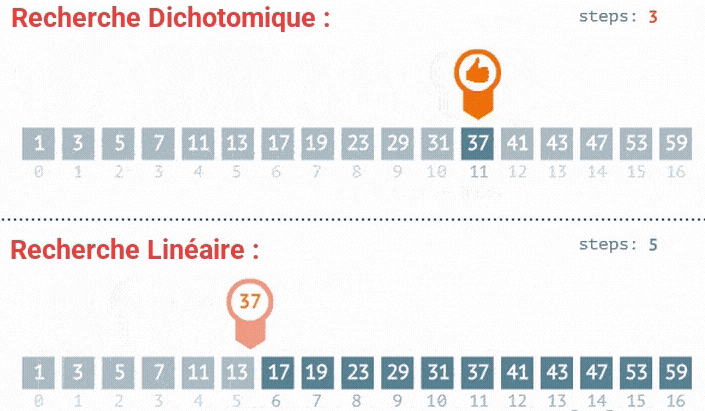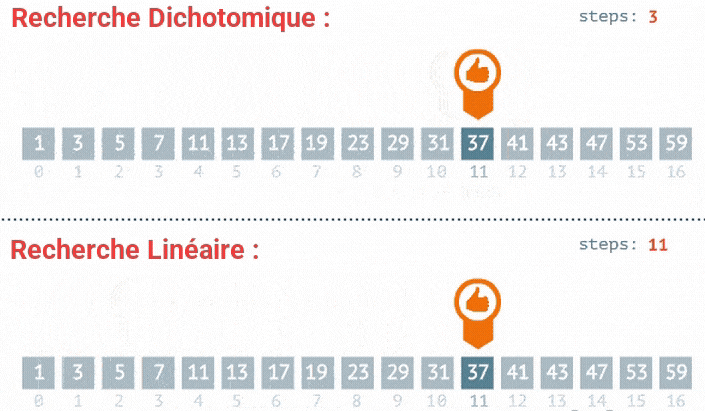
print(liste) # [1, 2, 4, 5, 8]6. Recherche Dichotomique (Binaire)
Fonctionnement :
La recherche dichotomique est un algorithme de recherche qui fonctionne sur des tableaux triés. Il compare la cible à l'élément du milieu du tableau. Si la cible est plus petite, la recherche continue dans la moitié gauche. Si la cible est plus grande, la recherche continue dans la moitié droite.
Exemple :
Prenons le tableau trié [1, 3, 5, 7, 9, 11] et cherchons la cible 7.
- Première itération : L'élément du milieu est
5. La cible7est plus grande, donc la recherche continue dans la moitié droite[7, 9, 11].
- Deuxième itération : L'élément du milieu est
9. La cible7est plus petite, donc la recherche continue dans la moitié gauche[7].
- Troisième itération : L'élément du milieu est
7, qui est égal à la cible. L'indice3est retourné.
La cible 7 est trouvée à l'indice 3.
def recherche_dichotomique(tab, cible):
gauche = 0
droite = len(tab) - 1
while gauche <= droite:
milieu = (gauche + droite) // 2
if tab[milieu] == cible:
return milieu # Trouvé, retourne l’indice
elif tab[milieu] < cible:
gauche = milieu + 1
else:
droite = milieu - 1
return -1 # Non trouvé
# Exemple
liste = [1, 3, 5, 7, 9, 11]
indice = recherche_dichotomique(liste, 7)
print(indice) # 37. Algorithme de Dijkstra
Fonctionnement :
L'algorithme de Dijkstra est utilisé pour trouver le plus court chemin entre deux nœuds dans un graphe pondéré. Il fonctionne en maintenant une liste des distances les plus courtes connues depuis le nœud de départ jusqu'à chaque autre nœud. À chaque étape, l'algorithme sélectionne le nœud avec la distance la plus courte connue et met à jour les distances de ses voisins.
Exemple :
Prenons un graphe avec les nœuds A, B, C, et D, et les arêtes suivantes : A-B (poids 1), A-C (poids 4), B-C (poids 2), B-D (poids 5), C-D (poids 1). Nous voulons trouver le plus court chemin de A à D.
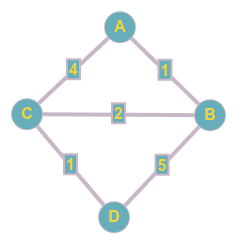
- Initialisation : Les distances initiales sont
A:0,B:∞,C:∞,D:∞.
- Première itération : Le nœud
Aest sélectionné. Les distances sont mises à jour :B:1,C:4.
- Deuxième itération : Le nœud
Best sélectionné. Les distances sont mises à jour :C:3(car1 + 2 < 4),D:6(car1 + 5).
- Troisième itération : Le nœud
Cest sélectionné. La distance deDest mise à jour :D:4(car3 + 1 < 6).
- Quatrième itération : Le nœud
Dest sélectionné. Aucune mise à jour n'est nécessaire.
Le plus court chemin de A à D est A -> B -> C -> D avec une distance totale de 4.
Voici le tableau des étapes de l'algorithme de Dijkstra pour ce graphe, montrant les distances minimales depuis A vers chaque nœud à chaque itération :
| Étape | Nœud traité | Distance A | Distance B | Distance C | Distance D | File de priorité |
| Init | — | 0 | ∞ | ∞ | ∞ | A |
| 1 | A | 0 | 1 | 4 | ∞ | B (1), C (4) |
| 2 | B | 0 | 1 | 3 | 6 | C (3), D (6) |
| 3 | C | 0 | 1 | 3 | 4 | D (4), D (6) (on garde 4) |
| 4 | D | 0 | 1 | 3 | 4 | — |
Chemin le plus court : A → B → C → D
Distance totale : 4
| Algorithme | Meilleur cas | Pire cas | Complexité moyenne | Remarque |
| Sélection | O(n²) | O(n²) | O(n²) | Simple mais lent |
| Insertion | O(n) | O(n²) | O(n²) | Bon pour presque trié |
| Fusion | O(n log n) | O(n log n) | O(n log n) | Stable, bon pour gros tableaux |
| Rapide (QuickSort) | O(n log n) | O(n²) | O(n log n) | Rapide en pratique |
| Bulle | O(n) | O(n²) | O(n²) | Pédagogique, peu utilisé |
| Recherche dichotomique | O(1) | O(log n) | O(log n) | Très efficace si trié |